

|
| published 11/02/99

Five years ago, when Australian postdoc Marc Wilkins coined the term proteome, it struck many observers as impossibly grandiose. At the time, few researchers were even contemplating a wholesale protein discovery effort on the scale of the Human Genome Project. Yet more rare was a business model for proteomics, and, in fact, only one real proteomics company (Large Scale Biology) existed.
Today, it's a very different picture. The term proteomics has entered the lexicon of biology and the field's aspirations have gained legitimacy, if not widespread acceptance. Moreover, dedicated proteomics companies have popped up all over the globe -- there were seven at last count, including one co-founded by Wilkins.
But for proteomics to become the new century's superhighway to biological knowledge, rather than a blind alley, it must first acquire or invent the technology to fit its grand aspirations. And timing is critical. With the Human Genome Project in its culminating phase, proteomics must either seize the moment or risk watching something else become the Next Big Thing. It's happened before. |

Back in 1980, years before the Human Genome Project was even a wisp of an idea, Congress seriously considered a Human Proteome Project. The term proteome, which refers to the proteins expressed by a genome, didn't, of course, yet exist, but the Human Protein Index, as it was called then, seemed like the logical next step in biology. Since proteins direct virtually all biological functions, didn't it make sense to systematically catalogue and classify them, and to learn how they change during disease?
But shifting political winds and the rise of genomics
cut short the project before it got started. "We proposed it, probably,
too soon," says proteomics pioneer Leigh Anderson. "Then the
DNA revolution got in between. But I believe we're going back to it."
(Anderson, then at Argonne National Laboratory,
now heads Large Scale Biology Corp.)
In fact, in a research paper that appeared last year in the scientific journal Electrophoresis, Anderson predicted that "by the turn of the millennium, if not much sooner, we will see a dramatic shift in emphasis from DNA sequencing and mRNA profiling to proteomics."
That hasn't happened yet. "I may have missed it by a couple of years," Anderson now says. "But the trend is definitely there. The interest of the pharmaceutical and diagnostic industries is ten-fold what it was a few years ago."
A handful of biotech companies are now exploiting that
interest. There were seven dedicated proteomics companies at last count
(see table), and at least two genomics companies -- Myriad
Genetics Inc. and CuraGen
Corp. -- have added proteomics capabilities to their repertoires. "Our
revenue is doubling every six months, probably," says Mary Lopez,
vice president of proteomics research and development at Genomic
Solutions Inc., which sells automated
proteomics systems and services. "It's tremendous. Our growth is
very, very fast."
|
Company
|
Location
|
Business
Approach
|
Major
Collaborators
|
| Ciphergen
Biosystems Inc. |
Palo
Alto, CA |
Protein
arrays |
N/A |
| Genomic
Solutions Inc. |
Ann Arbor,
MI |
Automated
2-D gel/MS platform |
N/A |
| Hybrigenics
SA |
Paris,
France |
Protein-protein
interaction mapping and databases |
Small
Molecule Therapeutics Inc.; Pasteur Institute |
| Large
Scale Biology Corp. |
Rockville,
MD and Vacaville, CA |
Biological
assay |
Biosource
Technologies Inc. (parent) |
| Oxford
GlycoSciences plc |
Oxford,
England |
Biological
assay; Protein databases |
Incyte
Pharmaceuticals Inc.; Pfizer Inc. |
| Proteome
Inc. |
Beverly,
MA |
Protein
databases |
N/A |
| Proteome
Systems Ltd. |
Sydney,
Australia |
Biological
assay; Protein databases |
Dow AgroSciences
LLC |

It's dawning on government grant study sections -- and drug companies -- that mass sequencing of genomic DNA, and spotting cDNA onto chips, may not lead to the promised land. Snazzy as these technologies are, they have a major shortcoming: They don't take into account pre-translational events and post-translational modifications of proteins. Protein activity -- particularly receptor activity -- relies heavily on phosphorylation, for example. DNA and mRNA reveal nothing about whether a given protein is active, and can badly deceive when it comes to estimating how much is there. Anderson has demonstrated that the correlation between mRNA and protein abundance is less than 0.5. "There doesn't seem to be any controversy over how weak this correlation is," says Anderson. "Everybody agrees it's pretty poor."
Measure proteins, not mRNA, evangelizes Anderson. Chip companies, in his view, offer clues as opposed to answers. "There are no drugs that are mRNAs, there are no targets that are mRNAs," he says. "The only purpose [of mRNA] is to tell you about proteins."
But proteomics remains a cottage industry. When Anderson
recently sold his fourteen-year-old company, Large
Scale Biology, to Biosource
Technologies, Inc., it had only thirty
employees. Genomic Solutions has about fifty involved in proteomics. Lopez
admits the field is "in an embryonic stage, getting close to toddlerhood,
maybe." At a time when mRNA expression arrays are spreading like
cell phones and Palm Pilots in big pharma and in academia, systems for
large-scale protein analysis are still novelties.
The problem: No one can agree on the best technology
for proteomics -- or even if it exists yet. "There are a lot of companies
out there...trying to develop technologies and saying, 'We have the solution,'
" says University of Michigan proteomics practitioner Phil
Andrews. "I haven't seen a solution,
something that solves all the problems."

Proteomics' workhorse technology, powerful but frustrating, is two-dimensional (2-D) gel electrophoresis. 2-D separates a cell's proteins on a gel based on their charge and mass, yielding a sheet of dark spots -- proteins -- suspended in a thin layer of acrylamide jello. When 2-D first arrived in the 1970s, "people thought it would revolutionize biology," says Andrews. Researchers thrilled at having a cell's protein complement physically separated out and seemingly ripe for the picking. "The problem was, we didn't know what these spots were, and to identify them took a tremendous amount of work," says Andrews. "And you could only get to the abundant ones."
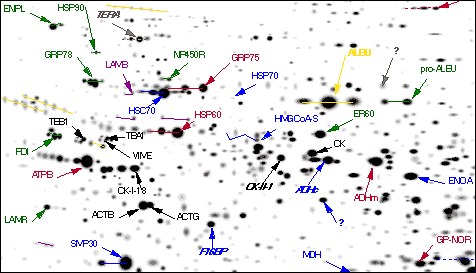
A detailed section of an F344 rat liver 2-D protein pattern.
Courtesy Large Scale Biology Corp.
A lot has happened since then. For protein identification,
the traditional, slow system of Edman sequencing has mostly given way
to mass spectrometry (MS). MS, in fact, now drives progress in proteomics.
In the same way that the whole vast enterprise of genome sequencing ultimately
rests on two machines (the Applied
Biosystems 3700 and the Molecular
Dynamics MegaBACE), so proteomics is
utterly dependent on new generations of mass spectrometers from companies
like Micromass, Finnigan,
and PerSeptive Biosystems.
These instrumentation companies are making progress. After decades of frustration, they learned in the early '80s to transform peptides in solid or liquid form to gas, making direct mass analysis possible. The year 1989 marked the arrival of MALDI, or Matrix Assisted Laser Desorption/Ionization, and electrospray ionization (ESI), both greatly expanding the range of proteins that could be analyzed with MS. In 1993 a fast, efficient way to identify proteins from MS was unveiled: protein mass fingerprinting. (Proteins are selectively cut with an enzyme, usually trypsin, and the fragment masses compared to theoretical peptides, from protein databases, similarly "digested" by computer.) If mass fingerprinting doesn't nail the protein, then the peptides can be further fragmented and analyzed in a second, "tandem" MS, or "MS/MS."
But proteomics technology still has a long way to go. Mapping the human genome was a trivial exercise compared to the sheer complexity that proteomics is facing. For example, most human genes express multiple distinct proteins, when one takes into consideration post-translational modifications and mRNA splicing. "It has been estimated that the number of actual proteins generated by the human genome, which is all the proteins of the proteome, if you will, is on the order of ten to twenty million," says Andrews.

Ways around this complexity are to work with the smaller model organisms like yeast (6,000 genes) and E. coli (4,500), or to just take a narrow look at individual pathways involving human proteins. But 2-D systems have other problems. Unlike DNA, proteins vary in abundance tremendously in a given cell -- by five or more orders of magnitude. And since there's no PCR for proteins, the scarce ones can't be amplified, and neither 2-D nor any other existing system can detect anything but a fraction in one snapshot. The scarce proteins are often critical control elements like protein kinases, or other important enzymes like telomerase.
And membrane proteins are hard to separate because they're insoluble without detergents. These proteins are often involved in cell-cell signaling, and make ideal drug targets, so their detection is critical. Finally, on a mechanical level, 2-D is labor-intensive, slow, and prone to contamination.
That's not a big deal, says Genomic Solutions' Lopez.
"It's an erroneous perception that the problem and difficulty in
proteomics is running 2-D gels," she says. "Even though the
process up front takes time, the amount of information that can be generated
is tremendous." Three thousand proteins or more can be seen on a
single gel, and they can be quantified. "The real bottleneck is not
2-D gels," says Lopez. "The real bottleneck is gel analysis
and mass spectrometry." (Loading proteins onto an MS plate, generating
spectra, and searching protein databases like SWISS-PROT
for matches takes time.) To speed things up, Genomic Solutions (and competitors
like Oxford GlycoSciences plc, Large Scale Biology and Proteome Systems
Ltd.) have automated the entire process, from extracting proteins from
the gel through protein identification and quantification. One system
can now plow through 200 proteins or more in a day.
But that may still not be good enough for high-throughput proteomics. To gauge the effect of knocking out all 4,500 genes in E. coli one by one, for example, assuming each one causes a change in twenty proteins, would mean identifying 90,000 spots. For a single system, that's still a multi-year task. (And automated image analysis software and robotic systems aren't foolproof.) Running multiple systems in parallel, of course, would add speed. But at some point cost becomes a barrier; a MALDI mass spectrometer will run between $200,000 and $350,000.

2-D is still evolving. Andrews is developing a system, called "virtual 2-D," that promises much faster performance. By using MALDI to scan proteins separated in only one dimension (charge), protein identification is incredibly fast. But the system can't yet quantitate proteins, and will be hard to use for complex organisms. Andrews is also working on loading 2-D gels directly into a mass spectrometer for reading. "Imagine a machine where you could map a thousand proteins an hour by MS," he says. Unfortunately, 2-D gels are not stable in the high vacuum of the mass spectrometer long enough to collect data. "We're working on ways to get around that problem," says Andrews. "And I think we'll get there."
Even if direct mass analysis of 2-D gels ends up working, anyone using 2-D faces a fundamental quandary: The system won't show many low-abundance proteins, because the spots are invisible, but pre-separation, or "fractionation" --which can resolve these spots -- makes quantitation impossible. High-abundance proteins can be removed in advance -- "peeling an onion to get down to the nifty ones inside," in Anderson's words. But there's never a clean cut, and any protein lost will skew measurements of relative quantity.
The quantitation dilemma is another reason that 2-D isn't ideal for high-throughput, "global" proteomics. Although the future promises better methods, such as high-performance liquid chromatography (HPLC) and capillary electrophoresis, researchers are stuck with 2-D for now. "It'll be an important part of proteomics for the next three or four years, at least," says Andrews. "I don't see an alternative. We don't have anything better than 2-D gels; it's the highest resolution technique we have."

Fortunately, technology is not standing still. Ruedi
Aebersold, a proteomics practitioner at the University
of Washington (Seattle), has devised
an ingenious method for measuring the relative quantities of proteins
using mass spectrometry. (See Gygi, S. et al. Nature
Biotechnology. 17:994-999
[1999] for details.)
Aebersold and Steve Gygi took two cell extracts, labeled them differently using stable isotopes, mixed them together, and separated proteins. Then they loaded them into a mass spectrometer, and measured the ratio of the two labels (and thus the relative mass). An interference phenomenon called ion suppression normally prevents this, but because the protein pairs being compared are virtually identical chemically, they're equally affected by ion suppression, so it doesn't matter. This system may also solve the pre-fractionation problem, since for pre-mixed proteins the relative ratio stays the same no matter how much protein is thrown out during fractionation. The technique, dubbed "ICAT" (Isotope Coded Affinity Tags) "is one of the most elegant things I've seen in proteomics since its inception," says Andrews.
Its impact remains to be seen. In theory, ICAT could make any separation technology, including HPLC and capillary electrophoresis, quantitative. (So far they're not.) It also promises to make 2-D gel electrophoresis more useful, by allowing pre-fractionation with quantitation.

One new separation technology -- already earning customer
raves and generating income -- is protein arrays. Ciphergen
Biosystems Inc., a three-year-old Palo
Alto biotech firm, sells a system based on an aluminum chip spotted either
with chemicals to bind proteins or with known antibodies to snare antigens.
A cell extract is placed on the chip, the target proteins bind, the rest
are washed off. Then the chip goes into a specialized mass spectrometer,
the "ProteinChip Reader," for analysis. Ciphergen marketing
director Gary Holmes says the system offers "a significant improvement
in speed and sensitivity" compared to other technologies.
But protein arrays have their limitations, too. "That technology has a lot of promise," says Mary Lopez. "But working with proteins is not as easy as working with nucleic acids." She points out that proteins, when they interact with a chemically treated surface, unfold and otherwise change the way they're shaped. So they behave differently. "It's not an absolute limitation, but it's a concern," she says. "The interaction that happens on a chip may not represent what happens in vivo. It's potentially fraught with artifacts."
Ciphergen has worked to minimize that problem. "We try to use conditions where we maintain native [protein] conformation," says Holmes. Whatever its limitations, Ciphergen's system has already proven useful. "In every case where we've tried to find uniquely expressed proteins, disease versus normal sample," says Holmes, "we've been able to find them."
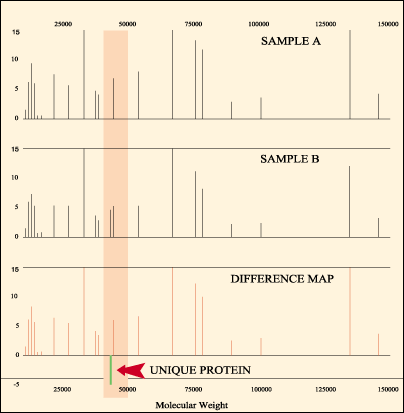
Differential protein expression profiling using Ciphergen's ProteinChip software.
Courtesy Ciphergen Biosystems Inc.
Still, a uniquely expressed protein may have nothing to do with the disease or drug effect under study. Verification of the function of proteins, found with any separation system, still will require "traditional" biology: Knock out the gene or inhibit (or enhance) its expression, evaluate the effect, put together a model. Proteomics can point the way, but it doesn't obviate the need for laborious downstream biology.
Proteomics practitioners dream of ultimately generating mathematical models that will predict biological processes. That's nowhere close. But even the immediate Holy Grail of proteomics -- a complete "proteome," or protein map of an organism -- is an impossible dream, because an organism's cells are always changing, and so is protein expression. "In fact, there is no such thing as a proteome of an organism," says Aebersold. "That's a nonsensical term...it implies that there is one thing that can be measured or listed, and that's exactly what we don't want to do. What we want to capture on the protein level is the complexity and dynamics of the system."
That task poses a monstrous bioinformatics problem.
To begin with, all the data generated will need compiling. "Celera
[Genomics] has three terabytes of hard disc space, and that's just getting
the DNA data," says Andrews. "The protein data is going to be
orders of magnitude greater in terms of quantity of data, and in heterogeneity."
(Data from all types of separation technologies will have to be compiled.)
Software, too, is lacking: As of now, no commercial information management
system exists for proteomics.
But the challenge is greater still. "Writing programs that capture the information obtained -- that's relatively simple," says Aebersold. "Where it gets complicated is when one tries to derive biological information out of whatever data one generates. Then it gets very complicated. That's essentially unsolved."

Meanwhile, proteomics companies have to make money, or at least put forward a business model attractive to investors. Like genomics companies, these firms offer platform technologies for discovering or screening drug candidates or diagnostic markers, and depend for their income on alliances with the drug industry. But, like genomics, proteomics is struggling to sell its services to a pharmaceutical industry that now regrets having overspent for libraries and screening methods that don't do a thing to speed drug development once candidates are in hand. Big pharma is wallowing in a glut of targets. Given the unfinished state of the technology, what added value can proteomics companies offer?
Four ways to sell proteomics have emerged so far: protein
arrays, interaction maps, data archives, and biological assays. Ciphergen's
model mirrors Affymetrix's:
sell a chip. (And, more importantly, a chip reader.) Having a shippable
product means an immediate income stream, instead of banking on future
drug discovery deals with big pharma. Ciphergen's chips run $49 each (bulk
rate), and the readers $150,000. As of mid-October, the company had sold
seventy readers -- more than $10 million worth. "Most pharmaceutical
companies have at least one of our systems," says Holmes.
Hybrigenics
SA, based in Paris, is commercializing maps of protein-protein interactions.
This approach builds on the yeast two-hybrid assay system first developed
a decade ago and now widely used.
Basically, separate binding and activation domains of a transcription activator gene are bound to the gene for a known protein (the "bait") and to gene fragments or cDNA clones in a library (the "prey"). When bait and prey themselves bind, the separate transcription domains connect and transcription of a reporter gene takes place, identifying a protein-protein interaction. Hybrigenics performs this assay by mating yeast, and any organism's genes can be tested. In 1997 scientists at the Pasteur Institute unveiled a system for doing many assays at once -- quickly, systematically and accurately. The French researchers reported a similar bacterial two-hybrid system last year.
Hybrigenics has an exclusive license for these new technologies. According to CEO Donny Strosberg, the company can test up to 100 million interactions in six weeks. Half the company's employees are involved in software development to handle the vast amount of data generated. "Without bioinformatics, you can't get anywhere," stresses Strosberg.
A small, privately held company of thirty employees, Hybrigenics depends heavily on collaborations. The Pasteur Institute is the most important, but it needs other collaborators to biologically validate the targets. And, once that's done, Hybrigenics needs help to select lead compounds for drug development. "Our hope is for these targets to identify high affinity ligands, and small molecules," says Strosberg. "That's going to be a lot of downstream work."
Hybrigenics has a collaboration with Small
Molecule Therapeutics Inc. of Monmouth
Junction, NJ, for target validation and drug discovery. But large combinatorial
libraries, for testing, can only come from big pharma. Hybrigenics so
far has no deals to report. "We're talking," says Strosberg.
"I'm excited about the level of interest."
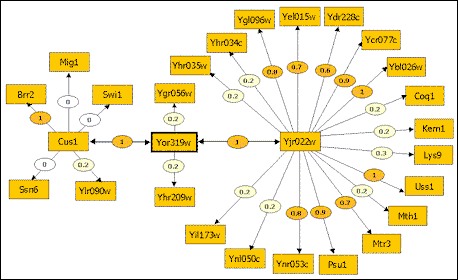
Protein interaction map of S. cerevisiae, including predicted biological scores.
Courtesy Hybrigenics SA.
Hybrigenics is also compiling whole-organism protein interaction maps for Helicobacter pylori (the bacterium that causes ulcers), hepatitis C, HIV, Staphylococcus and Streptococcus. Yeast and E. coli are also on the way. H. pylori is half done, says Strosberg, but yeast and E.coli will take "years" to complete. "The real question is, do we want to do it completely?" asks Strosberg. "[Or] do we want to do some pathways?"

That's the question all proteomics companies face: Whether to sell proteomics as a problem-solving tool (Is a particular drug toxic? What's the cause of atherosclerosis?) or to sell "library access" to a whole-proteome database? "Biological assay or data archive?" in Aebersold's words.
Proteome Inc.,
a five-year-old Beverly, MA, company, takes the data archive approach.
It sells access to three protein databases: yeast, Caenorhabditis
elegans, and
Candida albicans,
a fungal pathogen. Each listed protein commands a web page that is thoroughly
"annotated," that is, fleshed out with sequence, regulatory,
and functional information along with links to sources elsewhere. This
should be useful to companies seeking to understand human proteins (and
evaluate them as potential drug targets) by quickly referencing their
thoroughly studied homologues in model organisms.
Large Scale Biology is following the biological assay model, and is not selling database access, at least for now. "Our major thrust is marketing solutions to specific problems," says Anderson. One LSB approach is to "perturb" a biological system, either with a pathogen or with a drug, and to use the protein expression changes to find disease markers or drug candidates, or to evaluate drugs for toxicity. Marker discovery with proteomics, Anderson says, has already yielded results, and that's only the beginning.
"The diagnostics business is going to be completely revolutionized," he says, noting that the existing arsenal of markers came about largely by accident. With a systematic approach, "large numbers of protein markers are going to be discovered."

England's Oxford GlycoSciences
plc is the only proteomics company to go public to date, and it even has
its own drug pipeline. (A small-molecule drug for Gaucher's disease could
reach the market as early as 2001.) OGS originally spun off from Oxford
University to sell scientific instruments and chemicals related to carbohydrate
biology, but decided to focus on proteomics in 1995. Since then it has
implemented an automated 2-D/mass spec system to detect and analyze proteins
for inclusion in several databases -- human, microbial and animal -- with
access to be sold through its partner, Incyte
Pharmaceuticals Inc. (In October
the partners landed their first subscriber, AstraZeneca.)
OGS, like LSB, is offering to work with individual
companies to build customized proteomics databases for solving particular
problems. For example, it's collaborating
with Pfizer Inc. to identify drug targets
and disease markers for Alzheimer's disease and atherosclerosis, and with
Cellular Genomics
Inc., of New Haven, CT, to find novel proteins involved in the immune
response.
Proteome Systems
Ltd., launched last February and based in Sydney, Australia, hit the ground
running. Its founders had created the Australian Proteome Analysis Facility,
the world's first government-run proteomics institute, back in 1995, and
now are trying to build on Australia's historically prominent role in
proteomics to achieve commercial success. (The company has a major ag-biotech
collaboration with Dow AgroSciences
LLC, announced in February.) Proteome Systems is using MS and specialized
software to identify and characterize a whole range of post-translational
modifications -- a necessary but much neglected step towards understand
protein function. "Identification is a piece of cake," says
Marc Wilkins, the company's technology development program leader. "The
challenge is doing much more detailed characterization."
It was Wilkins, you recall, who coined the term "proteome" in 1994. "We realized the field had an enormous potential, to link proteins to genes in a high-throughput fashion," he recalls. "[But] we always had to use this cumbersome phrase, 'proteins expressed by a genome.'...[Now] the field has kind of been legitimized in the language."
Both selling database access and protein discovery figure into Proteome Systems' business plan. The company is compiling a database of known sugar structures for all species, and expects to land its first subscriber soon. (Glycosylation, the attachment of sugars to proteins, often regulates receptor activity.) It's also developing a new technology, called "chemical printing," for performing a wide range of chemical reactions -- for example, for separating and analyzing protein modifications -- on immobile proteins before mass spectrometry. And, like competitors, Proteome Systems has created an automated 2-D gel system and accompanying bioinformatics platform.

Proteomics technology is advancing by leaps and bounds, but the hurdles are greater than anything molecular biology has yet had to overcome. DNA can be amplified; proteins can't. DNA is a simple linear code defined half a century ago; proteins fold in baffling ways and interact unpredictably. DNA is basically static; proteins change in myriad ways even in an individual cell over a short period of time. How can proteomics sell itself when DNA (and RNA) are so much simpler, elegant, user-friendly? Should biologists and medicinal chemists (and investors) bother with global protein research, much less with a Human Proteome Project, when nucleic acids offer so much power at so little cost?
The answer is a resounding yes, says Leigh Anderson. The protein realm is essential to progress in biology. "It is the whole basis of fields like diagnostics, or pharmaceuticals," he says. "It can't be short-circuited just by saying that DNA is a lot easier to work with."
But isn't a 40 or 50 percent correlation between mRNA and protein expression good enough, given the advanced state of high-throughput nucleic acid technology? Not for diagnostics, Anderson points out. "You can't use iffy things," he says. "You have to have a quantitative marker that tells you what you're interested in."
What about for finding drug candidates, or working out cellular signaling pathways? "Yeah, I think you can get a bunch of good hints," says Anderson. "But the question is one of risk...If you're putting people onto non-existing problems based on this beautiful technology, that is a major problem.
"All of this work will be replaced by proteomics as we go forward," Anderson boldly predicts. "The whole cDNA/mRNA business is temporary." But until proteomics technology catches up to the vision, this scientific revolution will be on hold.
........................................................................................................
Cover Credit:
The three-dimensional molecular models of proteins
used as elements in
the cover art are based on images contained in the SWISS-3D
IMAGE
database of the ExPASy proteomics server of the Swiss
Institute of
Bioinformatics.
........................................................................................................ |